大模型
一般指大语言模型 (英语:large language model,LLM) 是一种语言模型,由具有许多参数(通常数十亿个权重或更多)的人工神经网络组成,使用自监督学习或半监督学习对大量未标记文本进行训练。大型语言模型在2018年左右出现,并在各种任务中表现出色。
尽管这个术语没有正式的定义,但它通常指的是参数数量在数十亿或更多数量级的深度学习模型。大型语言模型是通用的模型,在广泛的任务中表现出色,而不是针对一项特定任务(例如情感分析、命名实体识别或数学推理)进行训练。
尽管在预测句子中的下一个单词等简单任务上接受过训练,但发现具有足够训练和参数计数的神经语言模型可以捕获人类语言的大部分句法和语义。 此外大型语言模型展示了相当多的关于世界的常识,并且能够在训练期间“记住”大量事实。
- GPT———基于转换器的生成式预训练模型(英语:Generative pre-trained transformers,GPT)是一种大型语言模型(LLM),也是生成式人工智能的重要框架。首个GPT由OpenAI于2018年推出。GPT模型是基于Transformer模型的人工神经网络,在大型未标记文本数据集上进行预训练,并能够生成类似于人类自然语言的文本。截至2023年,大多数LLM都具备这些特征,并广泛被称为GPT。
- LLaMA———(英语:Large Language Model Meta AI,直译:大语言模型元AI)是Meta AI公司于2023年2月发布的大型语言模型。它训练了各种模型,这些模型的参数从70亿到650亿不等。LLaMA的开发人员报告说,LLaMA运行的130亿参数模型在大多数NLP基准测试中的性能超过了更大的、具有1750亿参数的GPT-3提供的模型,且LLaMA的模型可以与PaLM和Chinchilla等最先进的模型竞争。虽然其他强大的大语言模型通常只能通过有限的API访问,但Meta在非商业许可的情况下发布了LLaMA的模型权重,供研究人员参考和使用。2023年7月,Meta推出 Llama 2,这是一种可用于商业应用的开源 AI 模型。
- LaMDA———对话编程语言模型(英语:Language Model for Dialogue Applications,通称:LaMDA)是Google所开发的一系列对话神经语言模型。第一代模型于2021年的Google I/O年会发表,第二代模型则同样发表于次年的I/O年会。2022年6月,Google工程师布雷克·雷蒙恩(Blake Lemoine)宣称LaMDA已存在感知能力和自我意识,导致该模块获得广泛关注,科学界在很大程度上否定雷蒙恩的说法,并同时引发对图灵测试(测试机器能否表现出与人类相当的智慧水准)效力的讨论。2023年2月,Google发表基于LaMDA架构的对话式人工智能聊天机器人Bard,以因应OpenAI开发的ChatGPT。
- BLOOM (BigScience Large Open-science Open-access Multilingual Language Model)
- baichuan-7B———是由百川智能开发的一个开源的大规模预训练模型。基于Transformer结构,在大约1.2万亿tokens上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。在标准的中文和英文权威benchmark(C-EVAL/MMLU)上均取得同尺寸最好的效果。
AI相关架构
多层感知器(MLP)循环神经网络(RNN)长短期记忆(LSTM)门控循环单元(GRU)
卷积神经网络(CNN)残差神经网络(ResNet)变换器自编码器变分自编码器(VAE)生成对抗网络(GAN)
图神经网络(GNN)回响状态网络(ESN)神经图灵机(NTM)可微分神经计算机(DNC)
什么是AI大模型?
AI大模型是“大数据+大算力+强算法”结合的产物,凝聚了大数据内在精华的“隐式知识库”。包含了“预训练”和“大模型”两层含义,即模型在大规模数据集上完成了预训练后无需微调,或仅需要少量数据的微调,就能直接支撑各类应用。
简单来说,就是在大数据的支持下进行训练,学习出一些特征和规则,微调后应用在各场景任务中。目前,其主要在自然语言处理、计算机视觉、语音识别等领域得到广泛应用。
AI大模型具有很高的计算和存储需求,需要使用极为强大的计算设备和高效的算法才能训练和应用,所以参数量一般可以达到惊人的数十亿或者数千亿。例如OpenAI的GPT系列,最开始的GPT-1拥有1.17亿个参数,到GPT-3的参数已经到达1750亿个,最新的GPT-4没有给出具体的参数量,但根据推测,它或将接近万亿。
AI大模型的应用价值
在AI大模型兴起之前,AI模型基本上都是对特定应用场景需求进行训练的,即小模型。它属于传统的定制化、作坊式的模型开发方式。这也意味着除了需要优秀的产品经理准确确定需求之外,还需要AI研发人员扎实的专业知识和协同合作能力完成大量复杂的工作。这就导致了模型无法复用和积累,使得AI落地的高门槛、高成本与低效率。
而大模型在研发时就具备了更标准化的流程,它通过从海量的、多类型的场景数据中学习,并总结不同场景、不同业务下的通用能力,学习出一种特征和规则,成为具有泛化能力的模型底座。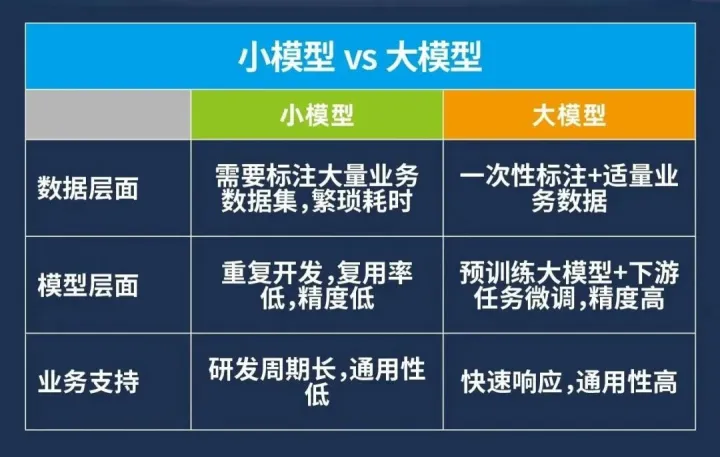
与传统的小模型生成模式相比,大模型能够大幅缩减特定模型训练所需要的算力和数据量,缩短模型的开发周期,并得到更好的模型训练效果。
可以说,大模型的真正意义在于改变了 AI 模型的开发模式,将模型的生产由“作坊式”升级为“流水线”。而模型开发模式的转变,使得 AI 技术在落地时拥有更强的通用性,可以泛化到多种应用场景。由此利用大模型的通用能力可以有效应对多样化、碎片化的AI应用需求,为实现规模推广AI落地应用提供可能。
AI和AI大模型区别
AI(人工智能)是指模拟、复制、扩展人类智能的科学与工程领域。它是通过机器学习、深度学习、自然语言处理等技术,使机器能够模拟和执行人类智能活动的分支。
AI大模型是一种具有巨大参数量的深度神经网络模型。这些模型通常由数十亿、甚至上百亿个参数组成,可以在大规模数据集上进行训练。AI大模型的典型代表是GPT-3(Generative Pre-trained Transformer-3),它是由OpenAI开发的自然语言处理模型,拥有1750亿个参数.
大模型的应用领域
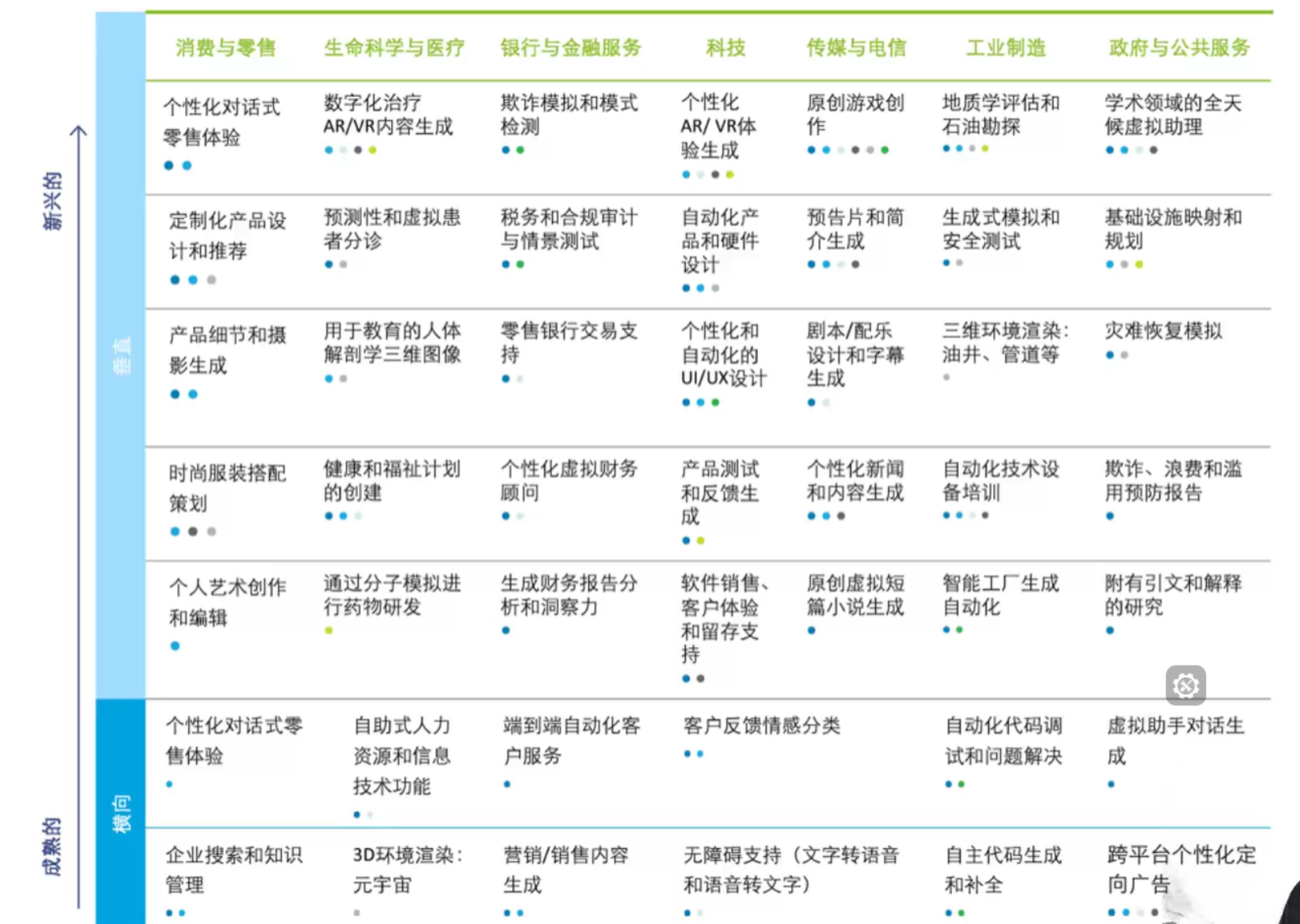
当然并不是只有这些的哈,还有很多的应用场景在等待着我们的开发。
以往基础技术升级,基本都是利好上层应用。但大模型很多时候不是这样。它的升级意味着上层辛苦构造的一些能力,大模型自带了,你没有价值增量了
比如你精调出一个数学大模型,而基础大模型也可以用数学资料做训练提升数学能力,再搭上物理、化学、计算机等一起泛化+涌现,它就抢走了你的市场。
究其根源,是大模型覆盖场景之多,前所未有。它不像操作系统等平台是有明确边界的。AI 能力的涌现,甚至不受设计者的控制,不知不觉间就吞噬掉更多场景。
咱们未来掌握大模型技术后,不仅是可以做独立开发者,前后端开发、测试、数据分析、设计等一个人都可以完成,现在一个人可以完成之前一个团队的事情,并且还能帮公司做私有化部署大模型,发展前景还是非常棒的.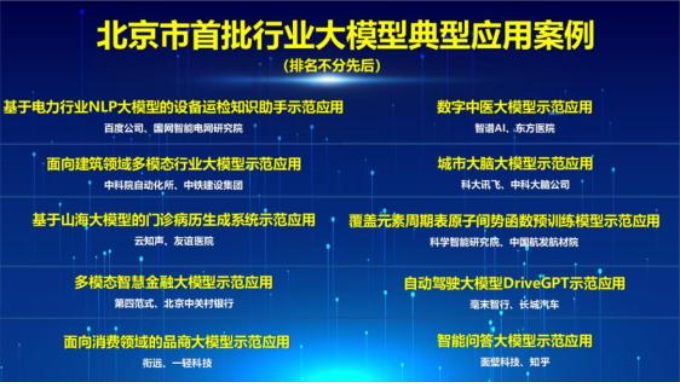
大模型技术为什么会这么多公司追捧呢?
核心就是两点 :效率高、想象力巨大。
效率高的事情
像孙志岗老师(哈工大副教授,得到副总裁)
开发的ChatALL.ai大模型全球github热榜第一,日本,美国专家都在评论 研究
过程中前端 后端 测试 产品 设计图片 UI都是利用大模型半个月开发完毕,正常效率是4 5个工程师 几个月的工作量。
他的能力 咱们也是可以做到的
另一位老师王卓然老师,他在模型训练,全栈工程实现领域都非常厉害,创始AI公司三角兽被腾讯10亿收购,作为独立开发者前后端 设计 产品等一个人完成,完成多个数百万金额项目 独立交付 这个能力我们也能掌握
想象力大
举例:
我们看百度的财报,看年度报,看这是一年有1000多亿的销售额,已经好多年了,就一年一千亿的销售额,还有100亿上下的净利真实性,你有多少互联网公司能做到很难的。现在的百度已经被很多公司蚕食了流量 但是还是那么强
但你有一个基于搜索的APP,它的APP里面是语音是按住说话,按住说话就像微信发消息一样,是有这个功能的,这是一个很简单的功能对吧?但这个事情现在就变得恐怖了,会不会按住说话打车,会不会按住说话去叫外卖?会不会按住说话说我想买冰箱帮我列举几个品牌,这些品牌大概价格不要超过3000块钱,帮我比价和比他的好评 可以做表格的
那产品是可以外链链接的,产品可以显示图片的,就可以它可以接入的,所以这个地方恐怖的地方就在于你通过按住说话,你可以调配的现实世界里面的资源,线下资源老多了,因为过去有无数的互联网公司
作为这些互联网传统公司,你要不要接入大模型的问题,比如说我美团是否允许我的商家和菜品和对我大模型说话就可以调配我的这些能力,那美团你不愿意有可能饿了么愿意,饿了不愿意,还有一堆第三方的小的愿意,
还有比如高德打车里面是一大堆小的打车软件对吧
这就是恐怖的地方 这是他一个能力 调用资源嘛 还有就是通过二次训练生成新的模型 解决传统线下问题.
大模型AI技术应用的四个层次
我们可以看下自己处于第几层的哦
什么是AI大模型全栈工程师?




